
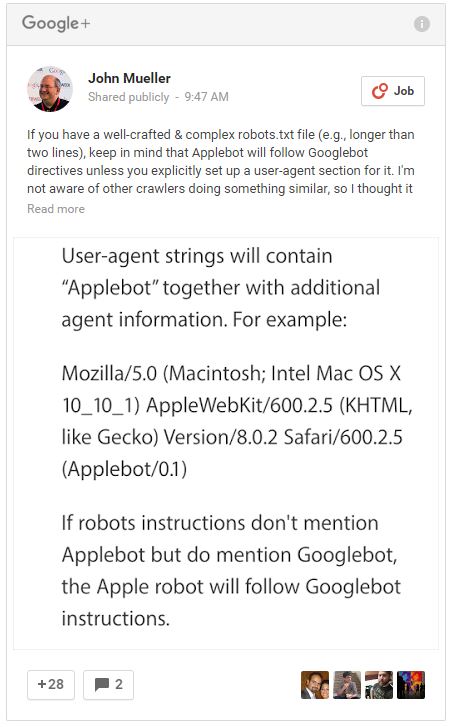
John Mueller hat auf Google+ einen kurzen Post über die Handhabung der Suchmaschinen-Crawler von Google und Apple in der robots.txt veröffentlicht. Darin griff er auf, dass der Applebot, sofern er nicht explizit in der robots.txt erwähnt ist, den Instruktionen des Googlebot folgt. Sofern ihr also den Applebot, der das Internet unter anderem für die interne Suche des Apple-Betriebssystems Mac OS X und die Sprachsuche Siri crawlt, von Eurer Webseite ausschließen oder nur bestimmte Bereiche crawlen lassen wollt, dann solltet ihr ihn in der robots.txt explizit ansprechen:
Zur Erinnerung: Robots.txt
Mit einer kleinen Textdatei namens robots.txt können Betreiber von Webseiten festlegen, wie Suchmaschinen mit Inhalten umgehen sollen. Hierbei kann z.B. festgelegt werden, dass bestimmte Unterseiten oder ganze Verzeichnisse von der Indexierung ausgeschlossen werden. Auch eine spezifische Angabe zu bestimmten Suchmaschinen ist möglich.


